Welcome
Hey there, I am Lio Qing.
Welcome to my blogs website, where I write down random thoughts, ideas, and topics here. Feel free to look around!
You can visit my personal website at https://lioqing.com.
Summary
2025
2026
Functional Template C++ Programming
2025-12-04
C++ is one of my first programming languages and I used to write a lot of C++ code in my early days. As a result, I have a pretty good understanding of the language and its features, including the complex yet powerful template system.
Since C++ template metaprogramming is turing-complete and C++ is basically the complete opposite of functional programming (before the addition of ranges library), so I got the idea of simulating functional programming with C++ template metaprogramming when I was studying a functional programming course in the spring semester of 2023.
And that, is exactly my topic today. Let’s go through my journey of rediscovering C++ template as a functional programming language, and take a look at how I built an arithmetic expression evaluator in it.
Note
The C++ code in this blog is compiled with MSVC and GCC using C++26 latest features.
MSVC compiler is at version
Microsoft (R) C/C++ Optimizing Compiler Version 19.44.35217 for x86and compiled withcl main.cpp /std:c++latest.GCC is at version
g++-14 (Ubuntu 14.2.0-4ubuntu2~24.04) 14.2.0and compiled withg++-14 main.cpp -o main -std=c++2c.The Haskell code in this blog is run with GHCi at version
GHCi, version 9.6.7.
C++ Template
Before diving into it, let’s get a basic overview of C++ template metaprogramming.
Templates are just smarter macros
C++ templates are basically macros, but more powerful than C macros. They can be used to generate structs, classes, or functions for it’s generic arguments as analyzed by the compiler in compile-time.
template <typename T> auto addition(T a, T b) -> T {
return a + b;
}
template <typename T> struct MyGenericStruct {
T my_data_of_type_t;
};
auto my_struct = MyGenericStruct<int> { .my_data_of_type_t = 1 };
int result = addition(my_struct.my_data_of_type_t, 2);
std::println("{} of type {}", result, typeid(result).name());
// 3 of type int
In the example above, because we instnatiated MyGenericStruct with an int as the generic argument, the compiler generates a MyGenericStruct<int> type. Similarly, because addition is supplied with int arguments, the compiler was able to infer the generic argument to be int, and thus generate an addition<int> function.
This is very useful for defining custom wrapper data types like std::vector which stores a collection of element of its generic argument.
Specialization helps hide implementation details
Specialization is one of the features that makes templates so powerful.
With specialization, the programmer defining the struct or function can use a different definition for specific generic argument.
For example, with a Vec4 struct template with a generic argument of type T.
template <typename T> struct Vec4 {
Vec4(T x, T y, T z, T w) : data{x, y, z, w} {}
auto get(std::size_t i) -> T {
return data[i];
}
private:
T data[4];
};
auto vec4f = Vec4<float>(1.0f, 2.0f, 3.0f, 4.0f);
std::println("size_of(vec4f) = {}", sizeof(vec4f));
// size_of(vec4f) = 16
We can then define a different implementation by defining a Vec4<bool> specialization.
template <> struct Vec4<bool> {
Vec4(bool x, bool y, bool z, bool w)
: data((std::uint8_t)x | (y << 1) | (z << 2) | (w << 3)) {}
auto get(std::size_t i) -> bool {
return (data >> i) & 1;
}
private:
std::uint8_t data;
};
auto vec4b = Vec4<bool>(true, false, true, false);
std::println("size_of(vec4b) = {}", sizeof(vec4b));
// size_of(vec4b) = 1
This way, we can guarantee Vec4<bool> takes up only 8 bits. Where as if we did not defina a specialization for it, Vec4<bool> may take up 4 times 8 - 32 bits.
This is because many compiler implementation uses 8 bits (1 byte) for bool for alignment purposes (and C++ standard doesn’t specify the size of bool).
Specialization as Pattern Matching
Because of the existence of template specialization, there must exist some kind of match and resolve mechanism in the compiler to find the specialization, which is the specialization matching system.
This mechanism is very similar to pattern matching, where in functional programming languages like Haskell, we can match arguments against specific constant values or data constructors, called patterns, to return a different value.
Using specialization matching as pattern matching
Since it is very common to use pattern matching to do branching in Haskell, let’s take a look at a simple example.
Take a fibonacci number function as an example. In Haskell, we would usually match against 0 to return 0, 1 to return 1, and the other values to the recursive calls.
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n - 1) + fib (n - 2)
-- >>> fib 7
-- 13
And given that C++ template also allows certain constant values to be the generic arguments, we can do the same in C++, which some of you may have seen it.
template <int N> auto fib() -> int {
return fib<N - 1>() + fib<N - 2>();
}
template <> auto fib<1>() -> int {
return 1;
}
template <> auto fib<0>() -> int {
return 0;
}
std::println("fib<7>() = {}", fib<7>());
// fib<7>() = 13
Of course, one downside of this approach is that the argument N must be a compile-time constant.
How about destructuring?
One key feature of pattern matching in Haskell is the ability to destructure components while matching the arguments.
For example, if we have a data constructor Vec2 with 2 arguments, or components, we can match against it to destructure it, in other words to bind its components to variables in the function. Here we bind the first and second component of Vec2 to x and y respectively, then we can use it to calculate the length squared.
data Vec2 = Vec2 Int Int
len :: Vec2 -> Int
len (Vec2 x y) = x * x + y * y
-- >>> len (Vec2 3 4)
-- 25
Now let’s try doing that in C++.
template <int X, int Y> struct Vec2 {};
template <typename T> auto len_sq() -> int {
static_assert(false, "Unsupported type");
}
template <int X, int Y> auto len_sq<Vec2<X, Y>>() -> int {
return X * X + Y * Y;
}
Oops, we ge the following errors!
MSVC: error C2768: 'len_sq': illegal use of explicit template arguments
GCC: error: non-class, non-variable partial specialization len_sq<Vec2<X, Y> >’
is not allowed
Turns out, partial specialization is not allowed on functions in C++ standard.
Using partial struct/class template specialization for destructuring
Well, GCC’s error message gave us a hint on how we might solve this issue - use it on a class!
But how are we going to define a function body and return value in a class? Since we are doing everything in compile-time, the most logical solution is probably to use a static constexpr.
template <int X, int Y> struct Vec2 {};
template <typename T> struct len_sq;
template <int X, int Y> struct len_sq<Vec2<X, Y>> {
static constexpr int value = X * X + Y * Y;
};
std::println("len_sq<Vec2<3, 4>>::value = {}", len_sq<Vec2<3, 4>>::value);
// len_sq<Vec2<3, 4>>::value = 25
And it works!
Struct/Class as Value
Now that we can pass arguments into and return values out of a template struct/class to treat it like a function, how do we construct and pass around more complex data structures like lists? After all, generic arguments can only be primitive types like int, or typename.
In fact, we have been doing it in the previous sections! Vec2 was basically holding the components as its member variables, and we were accessing its member variables by destructuring it. Although it is not a named member variable, it should be good enough.
Returning struct values
Okay, so we have figured out how to pass more complex data structures around, how do we return it?
For example, what if we want to extend Vec2 to a 3 components data structure Vec3? Here is how we would do it in Haskell.
data Vec3 = Vec3 Int Int Int
deriving Show
ext :: Vec2 -> Int -> Vec3
ext (Vec2 x y) z = Vec3 x y z
-- >>> ext (Vec2 1 2) 3
-- Vec3 1 2 3
In essence, we want to pass in a data structure, and get a data structure in return.
We can leverage the using alias to let callers access the return value via type alias.
template <int X, int Y, int Z> struct Vec3 {};
template <typename T, int Z> struct ext;
template <int X, int Y, int Z> struct ext<Vec2<X, Y>, Z> {
using value = Vec3<X, Y, Z>;
};
The caller just need to “call” the ext “function” using the syntax ext<Vec2<1, 2>, 3>::value.
As an important note, we should use using value = typename T::value; if the return value is the return value of another function call. This is required because of the way C++ parsers are defined needs to be able to know ahead of time that the alias is a type.
Outputting struct values
Hmm… let’s try to print it out.
std::println("ext<Vec2<1, 2>, 3>::value = {}", typeid(ext<Vec2<1, 2>, 3>::value).name());
// MSVC: ext<Vec2<1, 2>, 3>::value = struct Vec3<1,2,3>
// GCC: ext<Vec2<1, 2>, 3>::value = 4Vec3ILi1ELi2ELi3EE
The MSVC output looks fine, but look at the GCC output! There is no way that is readable.
Let’s try to define some way to output a struct in a more standardized way.
template <typename T> struct show {};
template <int X, int Y, int Z> struct show<Vec3<X, Y, Z>> {
static auto value() -> std::string {
return std::format("Vec3<{}, {}, {}>", X, Y, Z);
}
};
std::println("ext<Vec2<1, 2>, 3>::value = {}", show<ext<Vec2<1, 2>, 3>::value>::value());
// ext<Vec2<1, 2>, 3>::value = Vec3<1, 2, 3>
And this is much better!
Note
Input/output are runtime operations, there is no way to put that into compile time without any external tools.
This is why we can and should use a normal function to convert it into strings. It makes it easier to implement too because we can just use
std::format.
Building a list
With what we have, we can build one of the fundamental data structures in computer science, a list!
In functional programming, it is very common to use cons and nil to construct lists. Let’s see how they are defined in Haskell.
data Cons a = Cons a (Cons a) | Nil
deriving Show
-- >>> Cons 'f' (Cons 'o' (Cons 'o' Nil))
-- Cons 'f' (Cons 'o' (Cons 'o' Nil))
While in Haskell we had to use a to represent a generic type, in C++ template we don’t have to. This is because C++ template is not “typed”, as long as it is a typename, we can pass it in.
template <typename X, typename Xs> struct Cons {};
struct Nil {};
You may have noticed, this way we cannot pass in primitive types like int or char, since they are not typenames.
But like what Java does with wrapper primitive classes, we can make “wrapper primitive struct templates” so that primitive types can be passed into typename parameters.
template <char C> struct Char {};
template <int N> struct Int {};
Now we can construct and print a list!
using Foo = Cons<Char<'f'>, Cons<Char<'o'>, Cons<Char<'o'>, Nil>>>;
std::println("Foo = {}", show<Foo>::value());
// Foo = Cons<'f', Cons<'o', Cons<'o', Nil>>>
Reading a string
While like C, we can represent string as a list of chars, it is not convenient to specify characters one by one in Cons.
If we want to do that, we can make use of the fact that const char* can be passed as template arguments.
template <const char* Cs> struct Str {};
Next, we will need a StrView which resembles C++ standard library’s std::string_view where we will track the string itself, and the start and the end of the view.
template <typename S, std::size_t I, std::size_t N> struct StrView {};
This lets us iterate through the string in a recursive manner. For example, we can use it to convert a StrView to a Cons.
template <typename T> struct to_cons;
template <const char* S, std::size_t I, std::size_t N> struct to_cons<StrView<Str<S>, I, N>> {
using value = Cons<
Char<S[I]>,
typename to_cons<StrView<Str<S>, I + 1, N>>::value
>;
};
template <const char* S, std::size_t N> struct to_cons<StrView<Str<S>, N, N>> {
using value = Nil;
};
This way, we can create a Cons from StrView.
Note
The reason why we cannot do a C-style iteration over the string by incrementing
const char*and reading the first character until'\0'is because pointer arithmetic operations are not actually executed in compile-time.If we try the following program:
static constexpr const char inp1[] = "123"; static constexpr const char* inp2 = inp + 1; using InputStr = Str<inp2>;We would get the following errors when compiling the program.
MSVC: error C2371: 'main::InputStr': redefinition; different basic types GCC: error: ‘(((const char*)(& inp)) + 1)’ is not a valid template argument for ‘const char*’ because it is not the address of a variable
The next problem, is how do we convert a Str to StrView? We can actually make use of constexpr functions in this case, to calculate the length of the string at compile-time.
template <const char* Cs> struct to_cons<Str<Cs>> {
static constexpr std::size_t const_strlen(const char* str) {
std::size_t len = 0;
while (*str != '\0') {
++len;
++str;
}
return len;
}
using value = typename to_cons<StrView<
Str<Cs>,
0,
const_strlen(Cs)
>>::value;
};
And with this, we can convert any string literal into a list of chars!
static constexpr char bar_cstr[] = "bar";
using BarStr = Str<bar_cstr>;
using BarCons = typename to_cons<BarStr>::value;
std::println("BarStr as Cons = {}", show<BarCons>::value());
// BarStr as Cons = Cons<'b', Cons<'a', Cons<'r', Nil>>>
Higher-order functions
Another key feature of functional programming langauges is the ability to pass functions into higher-order functions. This enable some nice syntax for operating on wrappers like lists.
This is achievable through template-template parameters, something that I didn’t know until I started working on this!
Take the classic map function as an example, which takes a function f and a list (or any iterable) xs, and applies f on each element x in xs, i.e. xs = [x1, x2, x3, ...] => map(f, xs) = [f(x1), f(x2), f(x3), ...]
template <template <typename> typename F, typename Xs> struct map {};
template <template <typename> typename F, typename X, typename Xs>
struct map<F, Cons<X, Xs>> {
using value = Cons<
typename F<X>::value,
typename map<F, Xs>::value
>;
};
template <template <typename> typename F> struct map<F, Nil> {
using value = Nil;
};
Now let’s take a concrete example of adding 2 to every element in a list using the map function we just defined.
template <typename X, typename Y> struct add {};
template <int X, int Y> struct add<Int<X>, Int<Y>> {
using value = Int<X + Y>;
};
template <typename T> using add_two = add<T, Int<2>>;
using ConsOfInts = Cons<Int<2>, Cons<Int<3>, Cons<Int<5>, Nil>>>;
using ConsOfIntsPlusTwo = typename map<add_two, ConsOfInts>::value;
std::println("map<add_two, ConsOfInts>::value = {}", show<ConsOfIntsPlusTwo>::value());
// map<add_two, ConsOfInts>::value = Cons<4, Cons<5, Cons<7, Nil>>>
Let’s build a simple calculator!
With all these tools at our disposal, let’s build something a bit more complicated - a simple calculator.
To keep things short, we will not handle any parentheses and any operator precedence. Everything will be evaluated from left to right, and on non-negative single digit integer values only, an example of such expression would be 1 + 2 * 3 / 4 - 5 and the answer would be -3.
Starts with evaluating single operator
To get started, we can start small with a function that evaluates the result of a single operator’s operation. We want to handle the 4 basic operators: +, -, *, /, and evaluate them on 2 integers.
template <typename L, typename O, typename R> struct eval;
template <int L, int R> struct eval<Int<L>, Char<'+'>, Int<R>> {
using value = Int<L + R>;
};
template <int L, int R> struct eval<Int<L>, Char<'-'>, Int<R>> {
using value = Int<L - R>;
};
template <int L, int R> struct eval<Int<L>, Char<'*'>, Int<R>> {
using value = Int<L * R>;
};
template <int L, int R> struct eval<Int<L>, Char<'/'>, Int<R>> {
using value = Int<L / R>;
};
We also need some helper functions
To be able to evaluate expressions from left to right with multiple operators, we will need to accumulate the result after each operation.
In functional programming, this would usually be done with a fold function. Since we are evaluating from left to right, let’s define a foldl function that accumulate results from left to right.
template <typename Acc, template <typename, typename> typename F, typename Xs> struct foldl;
template <typename Acc, template <typename, typename> typename F, typename X, typename Xs>
struct foldl<Acc, F, Cons<X, Xs>> {
using value = typename foldl<typename F<Acc, X>::value, F, Xs>::value;
};
template <typename Acc, template <typename, typename> typename F> struct foldl<Acc, F, Nil> {
using value = Acc;
};
Nice, on top of that, we also need a way to convert characters to integers - a to_digit function. Since we are only operating on single digit integers, this is quite easy.
template <typename C> struct to_digit {};
template <char C> struct to_digit<Char<C>> {
using value = Int<C - '0'>;
};
Great! Now the final helper function - a Select function. While we can do branching via pattern matching, this will simplify branching for boolean conditions.
template <typename Cond, typename Then, typename Else> struct select {};
template <typename Then, typename Else> struct select<std::true_type, Then, Else> {
using value = Then;
};
template <typename Then, typename Else> struct select<std::false_type, Then, Else> {
using value = Else;
};
So now, we can do branching like the following.
typename select<std::bool_constant<42 == 6 * 7>, Char<'t'>, Char<'f'>>
Note
Note that the name
selectis deliberately distinct fromif. The bodies of anifstatement is lazily evaluated, i.e. only evaluated after the condition is checked and branching has occured, while the “body” of ourselectfunction is evaluated before the condition is checked.To define the equivalent of an
ifstatement for lazily evaluated branch bodies, we can define the following.template <typename Cond, typename Then, typename Else> struct if_ {}; template <typename Then, typename Else> struct if_<std::true_type, Then, Else> { using value = typename Then::value; }; template <typename Then, typename Else> struct if_<std::false_type, Then, Else> { using value = typename Else::value; };Notice the
::valuein the return value, this means we don’t need to write::valuewhen passing in the arguments, but this also means we cannot pass in any value as an argument due to the way we construct values, i.e. constructing values likeCons<Int<1>, Nil>does not require and cannot use::value.To remove this limitation, we can define “constructor” functions for struct/class values.
template <typename X, typename Xs> struct Cons { using value = Cons<X, Xs>; }; struct Nil { using value = Nil; };This way, we can use
if_with values as the bodies.if_< std::bool_constant<42 != 6 * 7>, Cons<typename Int<1>::value, typename Nil::value>, Nil >
The calculator
Finally let’s build the calculator.
We will first build an evaluator function which determines whether to call eval or store the value or operator into the accumulator.
template <typename Input> struct Calculator {
template <typename Acc, typename C> struct evaluator {};
template <int Value, char Op, char C> struct evaluator<
std::tuple<Int<Value>, Char<Op>>,
Char<C>
> {
using value = typename select<
std::bool_constant<
C >= '0' && C <= '9' ||
C == '+' || C == '-' || C == '*' || C == '/'
>,
typename select<
std::bool_constant<C >= '0' && C <= '9'>,
std::tuple<
typename eval<
Int<Value>,
Char<Op>,
typename to_digit<Char<C>>::value
>::value,
Char<'+'> // a placeholder for the next operator
>,
std::tuple<Int<Value>, Char<C>>
>::value,
std::tuple<Int<Value>, Char<Op>> // ignore invalid characters
>::value;
};
// ...
};
We would also need a get_result function to extract the reuslt, i.e. the integer, from the tuple of integer and operator.
template <typename Input> struct Calculator {
// ...
template <typename R> struct get_result {};
template <int Value, char Op> struct get_result<std::tuple<Int<Value>, Char<Op>>> {
using value = Int<Value>;
};
// ...
};
Finally we chain everything together: from Str to Cons, from Cons to Folded, from Folded to value.
template <typename Input> struct Calculator {
// ...
using Cons = typename to_cons<Input>::value;
using Folded = typename foldl<
std::tuple<Int<0>, Char<'+'>>,
evaluator,
Cons
>::value;
using value = typename get_result<Folded>::value;
};
Let’s see the result!
static constexpr char inp[] = "1 + 2 * 3 / 4 - 5";
using InputStr = Str<inp>;
using Result = typename Calculator<InputStr>::value;
std::println("Result of '{}' = {}", inp, show<Result>::value());
// Result of '1 + 2 * 3 / 4 - 5' = -3
Is there more?
And on top of what I shared in this blog post, there is so much more that can be done. To push my limitation of what to build in a “language” like this, the ultimate program I built is an arithmetic expression evaluator with parser combinators and variable substituion.
An example usage extracted from the source code.
// Inputs
constexpr char inp[] = "pi * r * r / 2 + (a + b) * h / 2";
constexpr char pi[] = "pi";
using InpStr = typename Literal<inp>::Eval;
using InpEnv = typename Env<
Tuple<typename Literal<pi>::Eval, Int<3>>,
typename Env<
Tuple<typename String<Char<'r'>, Nil>::Eval, Int<2>>,
typename Env<
Tuple<typename String<Char<'a'>, Nil>::Eval, Int<1>>,
typename Env<
Tuple<typename String<Char<'b'>, Nil>::Eval, Int<5>>,
typename Env<
Tuple<typename String<Char<'h'>, Nil>::Eval, Int<4>>,
Nil::Eval
>::Eval
>::Eval
>::Eval
>::Eval
>::Eval;
// Outputs
using OutParse = typename parse<pExpr::Eval, InpStr>::Eval;
using OutEval = typename eval<
InpEnv,
typename fst<typename unwrap<OutParse>::Eval>::Eval
>::Eval;
// Main
int main() {
std::cout << " InpStr: " << show<InpStr>::to_string() << std::endl;
std::cout << " InpEnv: " << show<InpEnv>::to_string() << std::endl;
std::cout << "OutParse: " << show<OutParse>::to_string() << std::endl;
std::cout << " OutEval: " << show<OutEval>::to_string() << std::endl;
return 0;
}
Conclusion
This has been a topic I wanted to share for a long time, it is super fascinating to me how the C++ template system can be so flexible, and how it is basically the opposite of procedural programming.
This has been an interesting journey, and I hope you enjoyed reading it as much as I enjoyed writing it!
Appendix
Full C++ source codeo of everything mentioned in this blog post.
#include <print>
#include <cstdint>
#include <typeinfo>
#include <string>
// C++ Template
template <typename T> auto addition(T a, T b) -> T {
return a + b;
}
template <typename T> struct MyGenericStruct {
T my_data_of_type_t;
};
// Template Specialization
template <typename T> struct Vec4 {
Vec4(T x, T y, T z, T w) : data{x, y, z, w} {}
auto get(std::size_t i) -> T {
return data[i];
}
private:
T data[4];
};
template <> struct Vec4<bool> {
Vec4(bool x, bool y, bool z, bool w)
: data((std::uint8_t)x | (y << 1) | (z << 2) | (w << 3)) {}
auto get(std::size_t i) -> bool {
return (data >> i) & 1;
}
private:
std::uint8_t data;
};
// Pattern Matching
template <int N> auto fib() -> int {
return fib<N - 1>() + fib<N - 2>();
}
template <> auto fib<1>() -> int {
return 1;
}
template <> auto fib<0>() -> int {
return 0;
}
// Pattern Matching & Binding
// template <int X, int Y> struct Vec2 {};
// template <typename T> auto len_sq() -> int {
// static_assert(false, "Unsupported type");
// }
// template <int X, int Y> auto len_sq<Vec2<X, Y>>() -> int {
// return X * X + Y * Y;
// }
// MSVC: error C2768: 'len_sq': illegal use of explicit template arguments
// GCC: error: non-class, non-variable partial specialization len_sq<Vec2<X, Y> >’
// is not allowed
// Pattern Matching & Binding
template <int X, int Y> struct Vec2 {};
template <typename T> struct len_sq;
template <int X, int Y> struct len_sq<Vec2<X, Y>> {
static constexpr int value = X * X + Y * Y;
};
// Returning Struct Values
template <int X, int Y, int Z> struct Vec3 {};
template <typename T, int Z> struct ext;
template <int X, int Y, int Z> struct ext<Vec2<X, Y>, Z> {
using value = Vec3<X, Y, Z>;
};
template <typename T> struct show {};
template <int X, int Y, int Z> struct show<Vec3<X, Y, Z>> {
static auto value() -> std::string {
return std::format("Vec3<{}, {}, {}>", X, Y, Z);
}
};
// String & Cons
template <typename X, typename Xs> struct Cons {};
struct Nil {};
template <char C> struct Char {};
template <int N> struct Int {};
template <typename X, typename Xs> struct show<Cons<X, Xs>> {
static auto value() -> std::string {
return std::format(
"Cons<{}, {}>",
show<X>::value(),
show<Xs>::value()
);
}
};
template <> struct show<Nil> {
static auto value() -> std::string {
return "Nil";
}
};
template <char C> struct show<Char<C>> {
static auto value() -> std::string {
return std::format("'{}'", C);
}
};
template <int N> struct show<Int<N>> {
static auto value() -> std::string {
return std::format("{}", N);
}
};
// String & Cons
template <const char* Cs> struct Str {};
template <typename S, std::size_t I, std::size_t N> struct StrView {};
template <typename T> struct to_cons;
template <const char* S, std::size_t I, std::size_t N> struct to_cons<StrView<Str<S>, I, N>> {
using value = Cons<
Char<S[I]>,
typename to_cons<StrView<Str<S>, I + 1, N>>::value
>;
};
template <const char* S, std::size_t N> struct to_cons<StrView<Str<S>, N, N>> {
using value = Nil;
};
template <const char* Cs> struct to_cons<Str<Cs>> {
static constexpr std::size_t const_strlen(const char* str) {
std::size_t len = 0;
while (*str != '\0') {
++len;
++str;
}
return len;
}
using value = typename to_cons<StrView<
Str<Cs>,
0,
const_strlen(Cs)
>>::value;
};
// Higher Order Functions
template <template <typename> typename F, typename Xs> struct map {};
template <template <typename> typename F, typename X, typename Xs>
struct map<F, Cons<X, Xs>> {
using value = Cons<
typename F<X>::value,
typename map<F, Xs>::value
>;
};
template <template <typename> typename F> struct map<F, Nil> {
using value = Nil;
};
template <typename X, typename Y> struct add {};
template <int X, int Y> struct add<Int<X>, Int<Y>> {
using value = Int<X + Y>;
};
template <typename T> using add_two = add<T, Int<2>>;
// Simple Calculator
template <typename L, typename O, typename R> struct eval;
template <int L, int R> struct eval<Int<L>, Char<'+'>, Int<R>> {
using value = Int<L + R>;
};
template <int L, int R> struct eval<Int<L>, Char<'-'>, Int<R>> {
using value = Int<L - R>;
};
template <int L, int R> struct eval<Int<L>, Char<'*'>, Int<R>> {
using value = Int<L * R>;
};
template <int L, int R> struct eval<Int<L>, Char<'/'>, Int<R>> {
using value = Int<L / R>;
};
template <typename Acc, template <typename, typename> typename F, typename Xs> struct foldl;
template <typename Acc, template <typename, typename> typename F, typename X, typename Xs>
struct foldl<Acc, F, Cons<X, Xs>> {
using value = typename foldl<typename F<Acc, X>::value, F, Xs>::value;
};
template <typename Acc, template <typename, typename> typename F> struct foldl<Acc, F, Nil> {
using value = Acc;
};
template <typename C> struct to_digit {};
template <char C> struct to_digit<Char<C>> {
using value = Int<C - '0'>;
};
template <typename Cond, typename Then, typename Else> struct select {};
template <typename Then, typename Else> struct select<std::true_type, Then, Else> {
using value = Then;
};
template <typename Then, typename Else> struct select<std::false_type, Then, Else> {
using value = Else;
};
template <typename Input> struct Calculator {
template <typename Acc, typename C> struct evaluator {};
template <int Value, char Op, char C> struct evaluator<
std::tuple<Int<Value>, Char<Op>>,
Char<C>
> {
using value = typename select<
std::bool_constant<
C >= '0' && C <= '9' ||
C == '+' || C == '-' || C == '*' || C == '/'
>,
typename select<
std::bool_constant<C >= '0' && C <= '9'>,
std::tuple<
typename eval<
Int<Value>,
Char<Op>,
typename to_digit<Char<C>>::value
>::value,
Char<'+'> // a placeholder for the next operator
>,
std::tuple<Int<Value>, Char<C>>
>::value,
std::tuple<Int<Value>, Char<Op>> // ignore invalid characters
>::value;
};
template <typename R> struct get_result {};
template <int Value, char Op> struct get_result<std::tuple<Int<Value>, Char<Op>>> {
using value = Int<Value>;
};
using Cons = typename to_cons<Input>::value;
using Folded = typename foldl<
std::tuple<Int<0>, Char<'+'>>,
evaluator,
Cons
>::value;
using value = typename get_result<Folded>::value;
};
// Main
int main() {
auto my_struct = MyGenericStruct<int> { .my_data_of_type_t = 1 };
int result = addition(my_struct.my_data_of_type_t, 2);
std::println("{} of type {}", result, typeid(result).name());
// 3 of type int
auto vec4f = Vec4<float>(1.0f, 2.0f, 3.0f, 4.0f);
std::println("size_of(vec4f) = {}", sizeof(vec4f));
// size_of(vec4f) = 16
auto vec4b = Vec4<bool>(true, false, true, false);
std::println("size_of(vec4b) = {}", sizeof(vec4b));
// size_of(vec4b) = 1
std::println("fib<7>() = {}", fib<7>());
// fib<7>() = 13
std::println("len_sq<Vec2<3, 4>>::value = {}", len_sq<Vec2<3, 4>>::value);
// len_sq<Vec2<3, 4>>::value = 25
std::println("ext<Vec2<1, 2>, 3>::value = {}", show<ext<Vec2<1, 2>, 3>::value>::value());
// ext<Vec2<1, 2>, 3>::value = Vec3<1, 2, 3>
using Foo = Cons<Char<'f'>, Cons<Char<'o'>, Cons<Char<'o'>, Nil>>>;
std::println("Foo = {}", show<Foo>::value());
// Foo = Cons<'f', Cons<'o', Cons<'o', Nil>>>
static constexpr char bar_cstr[] = "bar";
using BarStr = Str<bar_cstr>;
using BarCons = typename to_cons<BarStr>::value;
std::println("BarStr as Cons = {}", show<BarCons>::value());
// BarStr as Cons = Cons<'b', Cons<'a', Cons<'r', Nil>>>
using ConsOfInts = Cons<Int<2>, Cons<Int<3>, Cons<Int<5>, Nil>>>;
using ConsOfIntsPlusTwo = typename map<add_two, ConsOfInts>::value;
std::println("map<add_two, ConsOfInts>::value = {}", show<ConsOfIntsPlusTwo>::value());
// map<add_two, ConsOfInts>::value = Cons<4, Cons<5, Cons<7, Nil>>>
static constexpr char inp[] = "1 + 2 * 3 / 4 - 5";
using InputStr = Str<inp>;
using Result = typename Calculator<InputStr>::value;
std::println("Result of '{}' = {}", inp, show<Result>::value());
// Result of '1 + 2 * 3 / 4 - 5' = -3
return 0;
}
Full Haskell source code of everything mentioned in this blog post.
{-# OPTIONS_GHC -Wno-unrecognised-pragmas #-}
{-# HLINT ignore "Eta reduce" #-}
module Main where
{-# LANGUAGE NoImplicitPrelude #-}
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n - 1) + fib (n - 2)
-- >>> fib 7
-- 13
data Vec2 = Vec2 Int Int
len :: Vec2 -> Int
len (Vec2 x y) = x * x + y * y
-- >>> len (Vec2 3 4)
-- 25
data Vec3 = Vec3 Int Int Int
deriving Show
ext :: Vec2 -> Int -> Vec3
ext (Vec2 x y) z = Vec3 x y z
-- >>> ext (Vec2 1 2) 3
-- Vec3 1 2 3
data Cons a = Cons a (Cons a) | Nil
deriving Show
-- >>> Cons 'f' (Cons 'o' (Cons 'o' Nil))
-- Cons 'f' (Cons 'o' (Cons 'o' Nil))
addTwo :: Int -> Int
addTwo x = x + 2
consOfInts = [2, 3, 5]
consOfIntsPlusTwo = map addTwo consOfInts
--- >>> consOfIntsPlusTwo
-- [4,5,7]
main :: IO ()
main = putStrLn "Hello, World!"
How I Vibe Coded a Hiking Track Viewer
2026-03-25
I recently decided to try out full-on vibe coding on a personal project where I want a visualization of my weekly hikes. For years, I’ve been hiking around where I live every weekend as a way to refresh myself from the repetitive day jobs, and I have been tracking it with Google Fit.
One day, I found out that I can export and download the data using Google Takeout, and so I had the idea to make a map viewer that displays my hiking tracks over time.
However, since I am now a full-time software engineer, I don’t really want to spend that much time on coding all day, especially for a personal project like this. That’s when I decided I will finally try letting LLMs to code everything for me.
Note
Since this is a rather small project, I did not use any advanced LLM prompting techniques like tuning instructions or skills.
I also did not do everything in one session, I intentionally broke the conversations into different sections for specific reason explained later and for avoiding overflowing the context window.
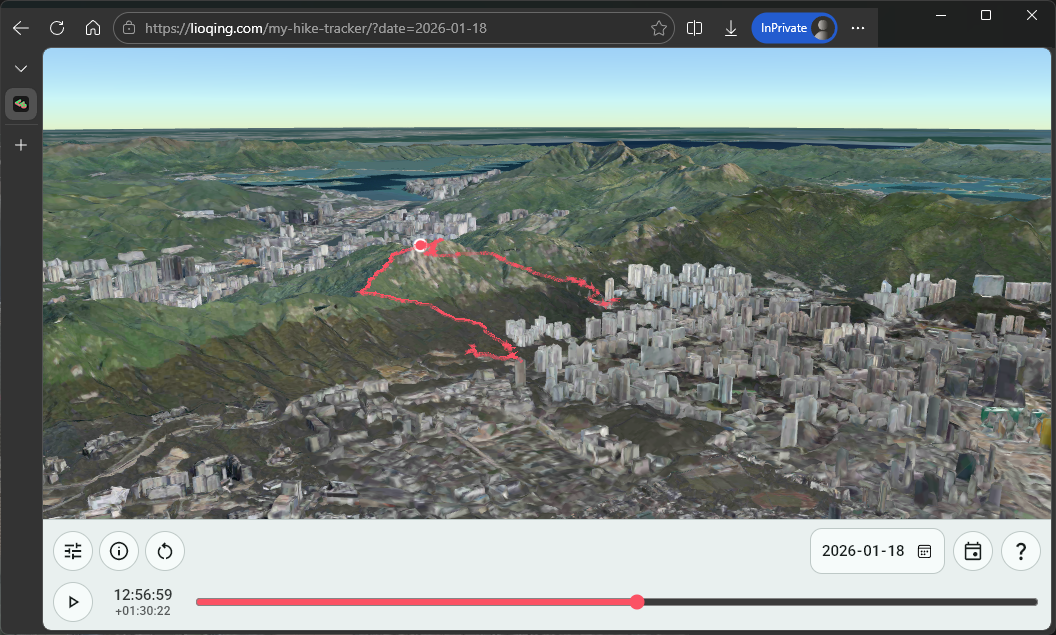
And it did work out for me, it only took me around 3 evenings prompting GitHub Copilot Pro. I am pretty satisfied with the result, you can visit it at https://lioqing.com/my-hike-tracker/.
My hike tracker demo.In the process, I applied a lot of ideas that I gained from previously coding with LLMs, but I also learnt something new about letting AI code an entire project. I’ll share them one by one in the following sections.
Data Source
Before talking about the website, I’d like to talk about where it all started. It all started with where I have my hiking track data.
I hike with Google Fit tracking my progress on my phone every weekend. While the UI of Google Fit is fine and does display useful information, I want to have a more personalized view of my progress.
Where to download the data
That is why when I found out I can download the Google Fit data from Google Takeout, I decided to make an app or website to display it in a cooler way.
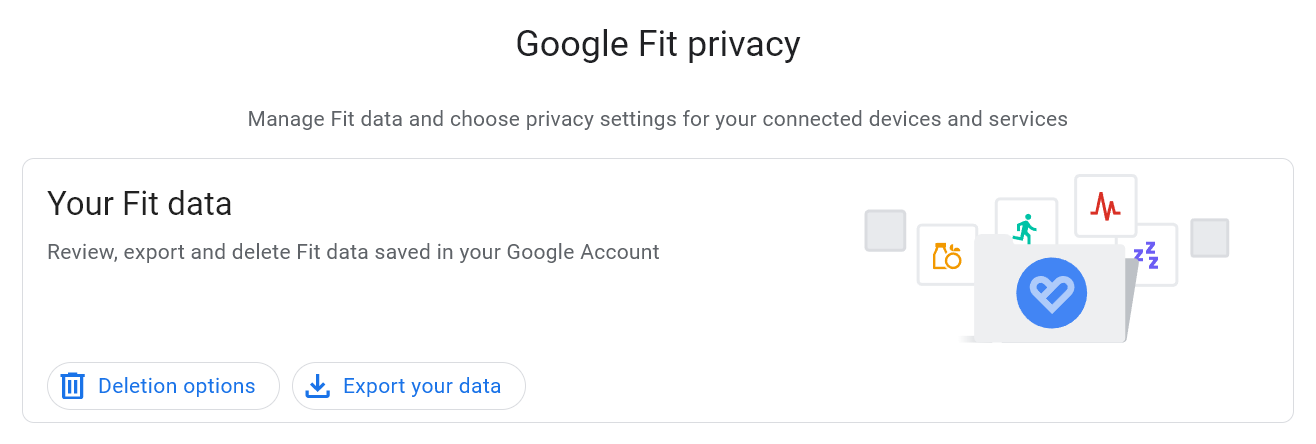 Google Fit privacy page where user can export their fit data.
Google Fit privacy page where user can export their fit data.
One unfortunate thing is that there is no option to choose a date range or activity type to download your fitness data, so for me, each time I download the data, I am downloading all my activities including hikes, walks, cyclings, etc. since I started using Google Fit in 2018.
The file format
Before I even start looking at the data, I asked Gemini (my choice of LLM for generic questions) how to extract timestamps and positions from the Google Fit data. This is when I learnt about the Training Center XML (TCX) file format.
It is a file format designed specifically for tracking exercises by Garmin in 2007. It is basically just an XML file with standardized entries.
With it being an established format, can now more confidently let codign agents to help me handle the technical details.
The Programming Languages and The (Lack of) Framework
I think this project is a pretty typical small-scale personal project for me, great for showing how I decide what tools to use for the tasks.
The languages
When it comes to these small personal projects, I have already established a simple rule of choosing what language to use and collaborate with coding agents:
- For simple tasks, use established and popular languages.
- Obviously the choice for building a website is just JavaScript.
- For complex tasks (which I may have to chime in and make changes myself instead of handing off everything to the agent), use languages I am familiar with.
- For the data extraction and cleaning, I chose Rust, where I want to make sure the ingested data for the website is correct.
- Most of the time, it is just Rust.
The vanilla web development experience
You may think that using a framework like React would be a great fit for it (which I also have experience in), but honestly I have almost never considered using React and instead just do vanilla HTML + CSS + JS because of the following reasons:
- LLMs have been trained on plenty of code examples for vanilla HTML + CSS + JS given that web standards are relatively stable compared to flashy frameworks.
- It is easy to deploy to GitHub Pages where I host all of my website frontends.
- Setting up a project and compiling/building my code is pretty time consuming.
- I just don’t like how state is managed in most frameworks.
Unless I absolutely want certain features or libraries from the ecosystem of the framework (especially for the beautiful animations and asthetics), I would prefer to just f**king use HTML.
The Collaboration with GitHub Copilot for Handling the Data in Rust
After brief consulting with Gemini to confirm the feasibility of reconstructing my hiking tracks using the Google Fit data, I decided to dive straight into building it.
After all, the only way to start something is to just do it.
Ingesting the data
At first, I searched up a crate for deserializing tcx format - tcx, and told copilot to start with that. Copilot tried using that crate to deserialize my file.
However, I got the following result when trying to parse one of my hiking TCX files.
ParseIntError: invalid digit found in string
I suspect this is due to the crate being updated over 4 years ago, which means it is probably outdated if the TCX format has been updated or Google Fit uses a custom TCX format.
So I had to find another solution.
I went ahead and took a look at the dependencies of the tcx crate, I found that it just uses serde with some XML serde deserializer crate. I decided to give copilot a try on just writing a custom TCX deserializer by using serde and whatever XML serde deserializer it wants to use.
After a couple of prompts (to let copilot know that it can test using my TCX file and to further specify the format I want), I was able to extract the timestamp, latitude, and longitude from each hike!
=== C:\Users\s2010\Downloads\takeout-20260221T061429Z-3-001\Takeout\Fit\Activities\2026-02-08T07_43_23.438+08_00_PT1H19M30.202S_Hiking.tcx ===
1770507805634 -> 22.283260345458984,114.13562774658203
1770507806472 -> 22.283279418945313,114.13563537597656
1770507807250 -> 22.283302307128906,114.1356430053711
...
After successfully extracting the timestamp, latitude, and longitude, I just need to write it to a file for the website to consume. I decided to use CSV as it should be the most straightforward solution.
And it is indeed the most straightforward solution, I opened a new chat session and copilot was able to get it done in just one prompt. I simply told it to write the result to a headerless CSV file with the columns being the timestamp in UNIX seconds, and latitude and longitude in high precision.
After that, I just told copilot to do some chores like refactoring into functions and adding CLI arguments using clap.
Additionally, I did some documentations myself for the CLI arguments to keep my future self in context in case I want to further develop or reference the code in future.
Cleaning the data
While I added the cleaner at almost the end of the project, I want to group it to this section because the process was similar to extracting the data.
When I was checking out my hiking tracks in the website, I realized that sometimes due to me forgetting to complete the tracking in Google Fit app, my positions when I was on railway would get recorded. It makes me look like I am flying across the city.
Me flying across the city.So I created another Rust project for removing unwanted data points using boolean expression filter rules.
I looked up expression evaluation crates, and found evalexpr. It was exactly what I wanted, it can evaluate to boolean, substitude variables, and even uses comments to document my filter rules.
The implementation process was very straightforward as well, the chat session only took me 2 prompts. First one for telling copilot to use the evalexpr crate to let user use the extracted data with their corresponding column names in a single column CSV file to filter data points from the extracted data. Second one for telling copilot to remove the header (for some reason it decided to add one named ‘expression’).
And the result is the following expected format.
!(timestamp > 1767456000000 && timestamp < 1767495660000) // 2026-01-04 before 11:01: tracking bugged at the start
!(timestamp > 1769925420000 && timestamp < 1769961600000) // 2026-02-01 after 13:57: forgot to turn off tracking in MTR
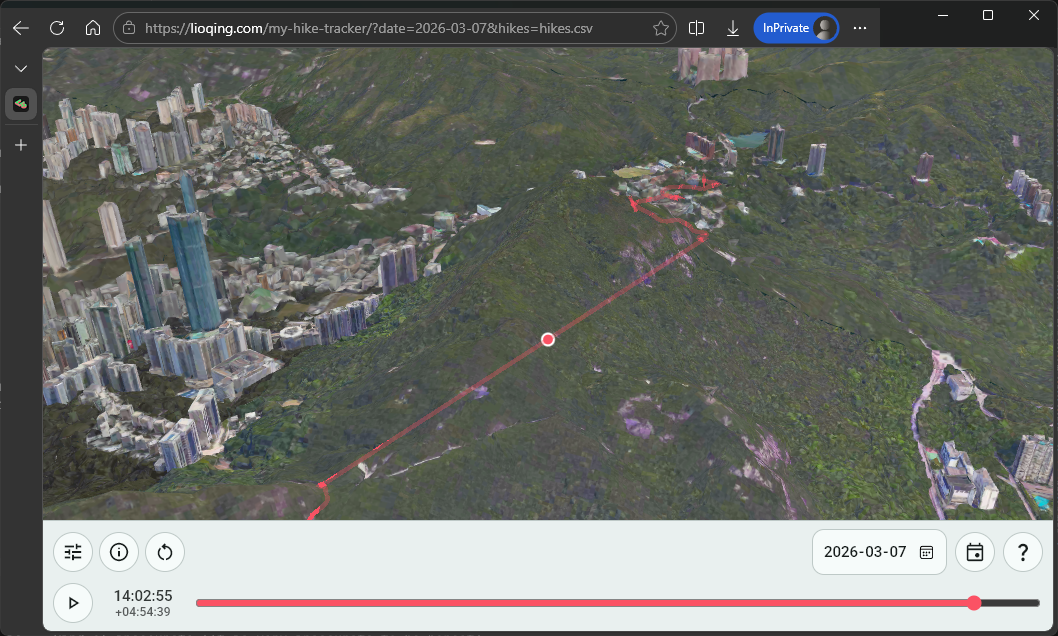 Track with missing data.
Track with missing data.
It certainly makes the visualization a lot more unpleasant to watch, so I had to find a solution.
While Google Fit itself uses some kind of weird algorithm to try to estimate the missing positions in between, the result is… kind of inaccurate (It is very inaccurate to be honest).
After making sure everything behaves exactly as I expect, I did the same thing as the extractor project. Manually did some documentation and told copilot to refactor some functions into different modules.
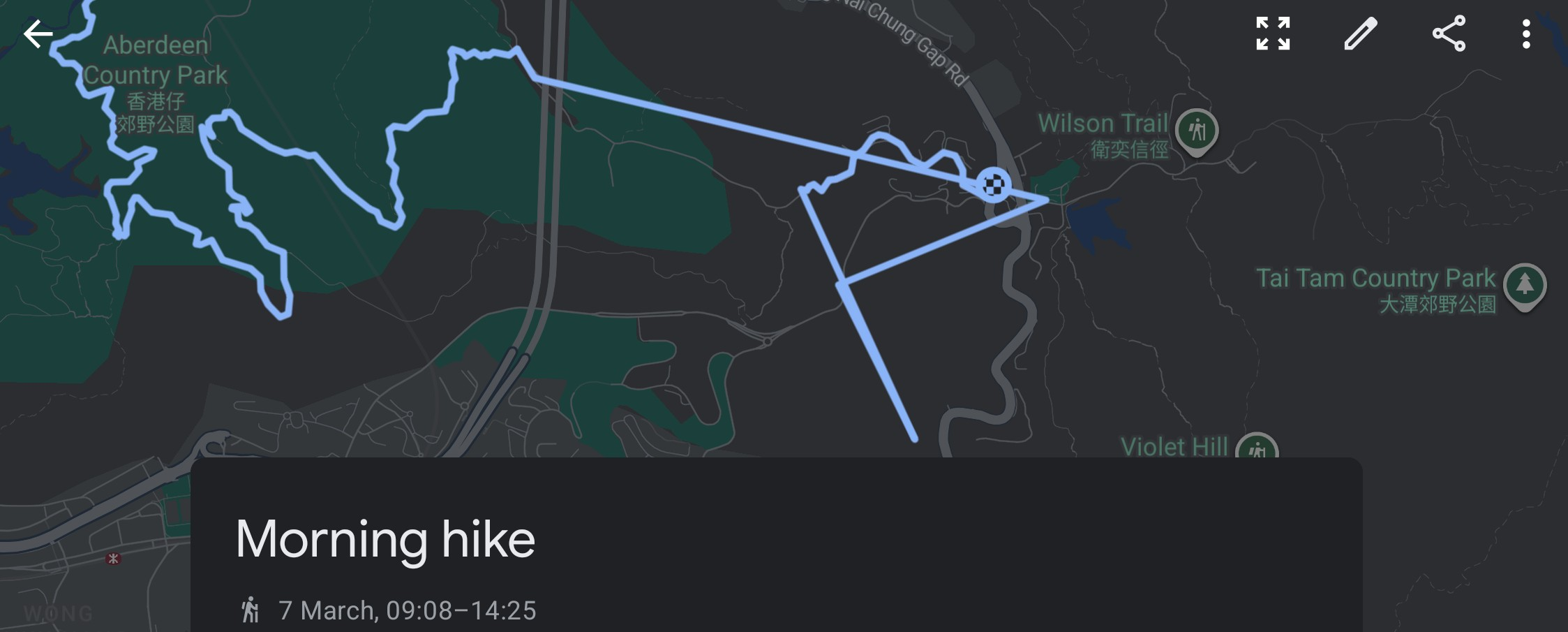 Google Fit with missing data.
Google Fit with missing data.
So at the end I decided to just let copilot to implement a manual solution - let the user enter the timestamp during extraction with a supp.csv optional file in the following format:
2026-03-07 11:40:00,22.257119218707395,114.16070126817006
2026-03-07 11:41:00,22.25710742147126,114.16132644010563
2026-03-07 11:42:00,22.257874943823307,114.16142850051098
...
And the result looks good enough in my opinion.
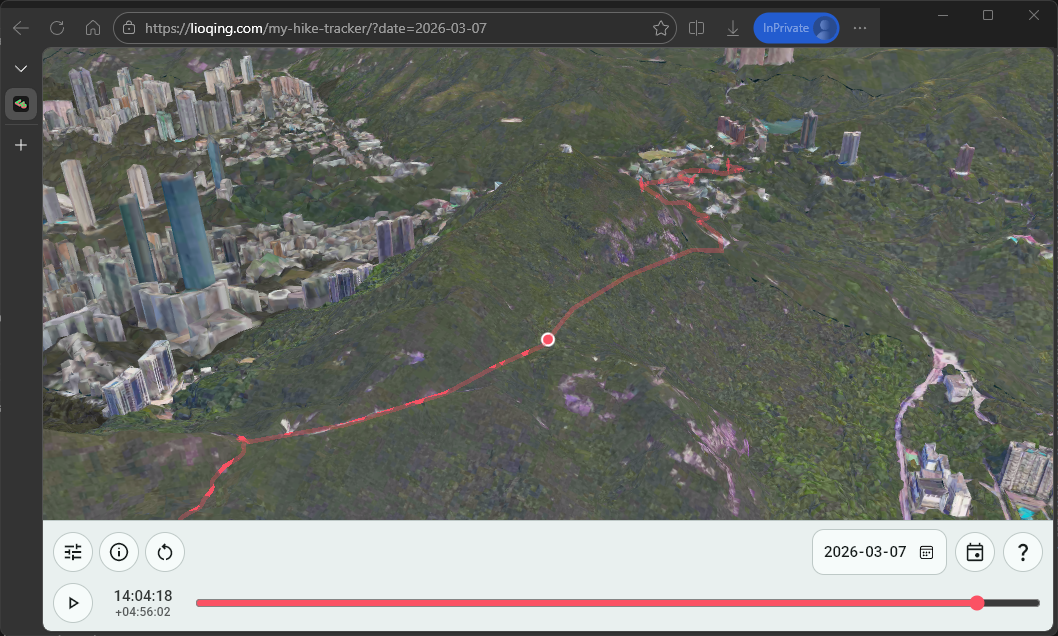 Track with supp data.
Track with supp data.
Lastly, I told copilot to clean all these up by making the program takes CLI arguments using the Clap crate, which I am very familiar with. I made some minor adjustment after copilot’s edit and told copilot to break up the one big main file into small modules.
Letting GitHub Copilot to just be the Pilot in HTML, JS, and CSS
Getting the visualization in was the biggest uncertainty about this project as I didn’t know the best way to make a map viewer. Fortunately, I found out CesiumJS later which saved my a lot of work.
The Failed Early Attempt at a 2D LOD Map Rendering
I attempted to screenshot Google Map in different resolution and then render them individually in the beginning. I was surprised to find that copilot was able to do it very quickly, and it looked like it worked perfectly at first. But then I found out it doesn’t work on less powerful devices like laptops and phones.
2D LOD map with issues in phone.The issue was most likely the many LOD chunks. I was using 4K images per chunk and hoping it would work, but apparently some devices are just not powerful enough to render multiple 4K images at certain zoom level…
The whole point of putting a viewer like this on the website is so that I can view it anywhere, which is also the reason I got into web development. (I am not a big fan of the current mainstream web development technologies, I am here just for the cross-platform compatibility!)
Open3Dhk and CesiumJS
Then one day during work, I found out during a conversation with coworkers that the Hong Kong Lands Department has a project called Open3Dhk that provide high quality 3D landscape model. Looking into the website, I found out it uses a very simple API to render the 3D map - CesiumJS.
Note
Yes, for some reason I did not look into any existing API for rendering maps in vanilla JS… My research and planning ability still have a lot to improve.
I immediately told copilot to try the API by giving it some examples from the Open3Dhk website. And it worked instantly!
Wow, that was way easier than what I did with all that LOD chunked rendering.
Finishing Up the Features
I had many features in mind, but all of them are basically completely implemented by copilot and I did not take a look at any of the technical details. This includes:
-
The playback controls
-
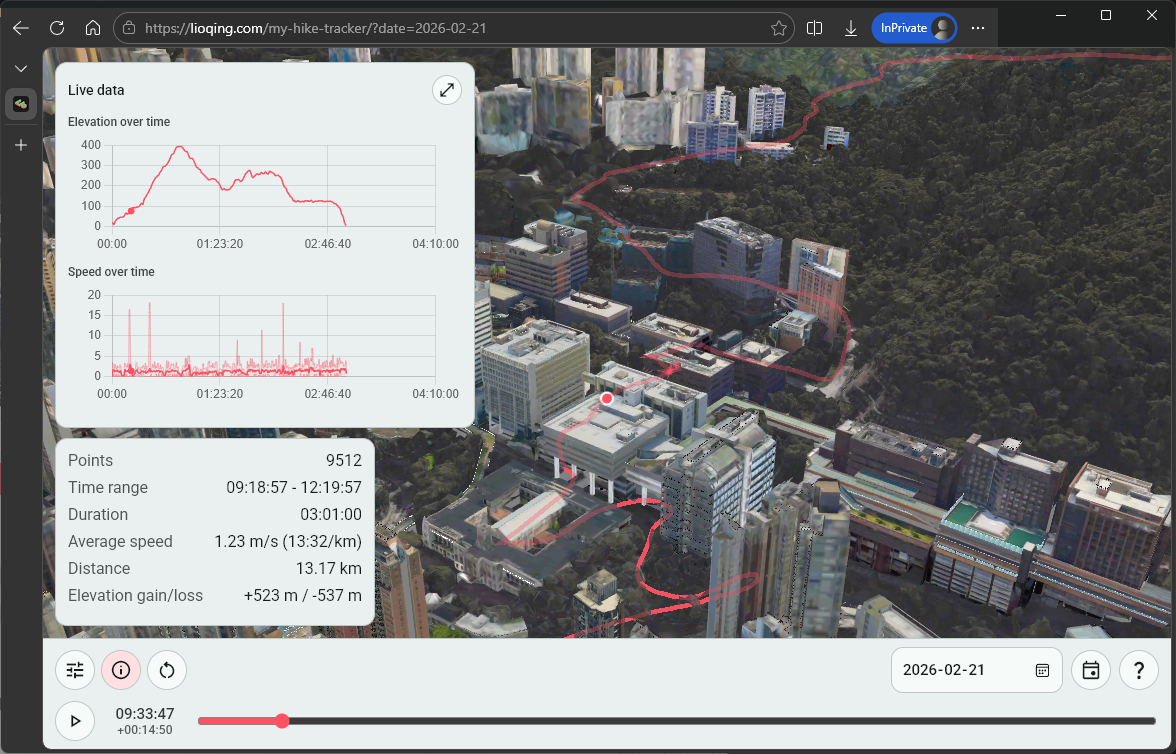
The information panel for both general information and live data during playback
-
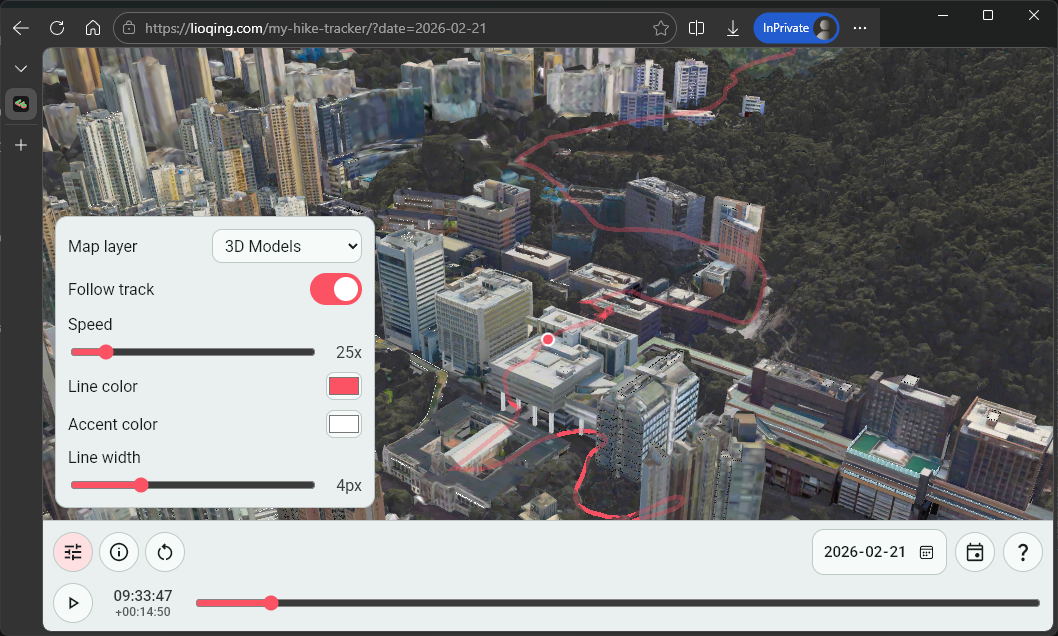
The selection of different layers like 2D contour map, 2D satellite map, 3D models, etc.
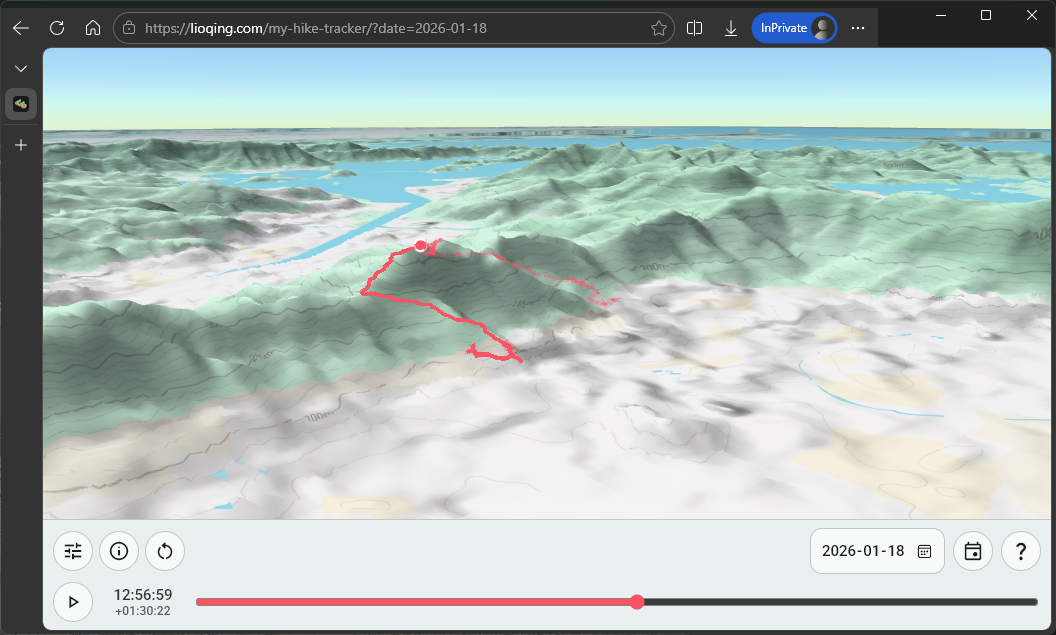
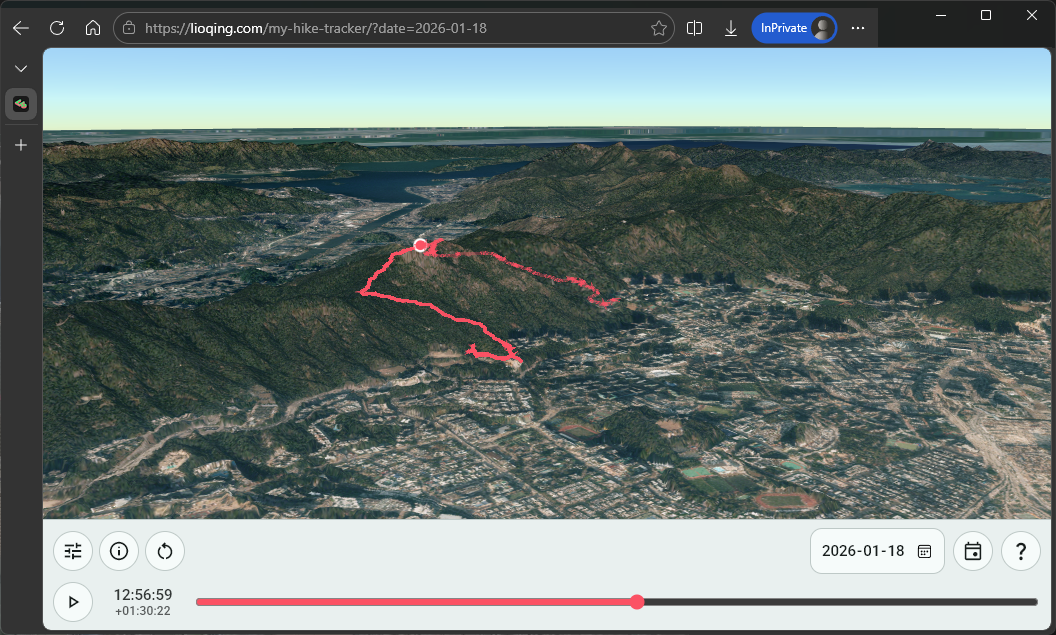
Of course, I had to find the resources for copilot to use, some of which are Cesium Ion for hosting the map assets and the Digital Terrain Model for Hong Kong from Lands Department for having a realistic height for the 2D layers.
One key difference on how I interact with copilot when I was working on the viewer is that I hand off a lot more decisions (especially technical decisions). For instance, I have no idea how are the longitude and latitude mapped to the terrain, nor am I aware of the algorithm it uses to calculate distance and speed. This makes me be less aware of the technical feasibility of features or changes I want.
Overall, it still works quite well though.
Conclusion and Reflection
In this project, I took 2 approach to vibe coding on 2 different parts of the project.
-
For the data handling, I designed and planned almost every implementation, I designed the functional requirements and checked the technical feasibility of the methods I decided to use. Then handed the actual coding part of it to copilot, which I provisioned carefully all lines of code generated despite not writing any myself. Copilot is essentially just a very powerful autocomplete, or english-to-code translater, and although I had to spend more effort in making sure my prompts are correct and clear, it worked relatively well.
-
For the viewer, I designed only the functional requirements and researched some resources for it. I left all the technical decisions and implementations to copilot, I don’t even look at any lines of code generated by it (with the exception of some configuration numbers and strings). In this case, copilot acts like a junior engineer for me, I have to point it to the right direction, and it has to find the path itself. However, it sometimes would assume what I said have to be done, even when the technical feasibility is questionable. When the result is not satisfactory to me, I would either force it to try again to match what I want, or I have to explicitly ask copilot to analyze the technical feasibility. Copilot not being able to question my decision is a big weakness in this approach, wasting some time and effort.
For a long time, I’ve been thinking that AI agents not being able to question the decision made by the user is a big weakness in human-AI communication, which is also why I think the second approach can leave a lot of issues hidden in the code. I believe vibe coding without any software engineering knowledge is definitely unsustainable and risky.
And I think the future of coding AI agents should definitely be improving the communication aspect of it, just like any software engineer needs to learn how to manage their projects and express their concerns towards the functional requirements to the project manager. And I do see some improvement in this area as I remember in this project that copilot asked for clarification in one of my prompts, so hopefully it will be much better at asking for clarifications in the future.
Note
The website is still receiving more features, such as drag and drop the csv into the website to display any file’s track!